素人でもできる! WEBページの情報を抽出する
ネットショップをされている方なら、WEBサイトで『New Item』や『目玉商品』を紹介するときに、各商品ページの情報(価格、商品名、リンク先の情報など)を抽出できたら、便利ですよね。それぞれの商品ページを開かなくても、必要な情報だけ取り出してみましょう。また、カテゴリページで複数の商品が並んでいるときに、それぞれの商品IDだけでも取り出せたら便利なことありませんか?例えば商品を出品した順番(もしくは古い順番)に商品IDを取りだしたいときなど。
①商品ページの情報(価格、商品名、リンク先の情報など)を抽出する。
②カテゴリページの商品IDを取りだす。
以上、2点について、PHPを使った素人レベルの解決策を考えていきますね。
作るのはPHPファイルです。phpはhtmlを生成してくれる言語です。
(※phpとhtmlは混在できます。<?php ・・・ ?> で囲まれた部分がphpです。)
PHPファイルはサーバー側で動くので、レンタルサーバーを借りている方は、サーバーに作ったファイルをアップします。レンタルサーバーがない方は、完全に無償で利用できるPHP開発環境の『XAMPP(ザンプ)』をインストールして、インストールされた[xampp]フォルダの直下にある[htdocs]フォルダにファイルを保存します。
まずは、商品ページの情報(価格、商品名、リンク先の情報など)を抽出します
WebサイトからWebページのHTMLデータを収集して、特定のデータを抽出することを「Webスクレイピング」といいます。これから、PHPのライブラリである『PHP Simple HTML DOM Parser』を使ってWebスクレイピングしちゃいます。ここで作るphpファイル名を「index.php」としますね。
考え方の順番としては、
【1】まずは、↓↓↓ここ↓↓↓から、ライブラリのsimple_html_dom.phpをダウンロードして、index.phpと同じフォルダに保存し、それを読み込みます。
| require_once ‘simple_html_dom.php’; |
| include_once(‘simple_html_dom.php’); |
※require_once、include_onceは同じ働きをします。
【2】str_get_html、file_get_html、file_get_htmlなどのヘルパー関数を使って、simple_html_domオブジェクト(= $html)を生成(=WEBページの情報を取得)します。
| // 文字列から $html = str_get_html( ‘<html><body>Hello!World!</body></html>’ ); |
| // URLから $html = file_get_html( ‘http://test.com/sample.html’ ); |
| // HTMLファイルから $html = file_get_html( ‘test.html’ ); |
【3】ページ内の要素についている「ID名」や「クラス名」を使って、生成したオブジェクト(= $html)から特定の要素を探しだして、変数(=$ret )に代入します。
| // id属性がcontentsのすべての要素を取得する $ret = $html->find( ‘#contents’ ); |
| // class属性がsubのすべての要素を取得する $ret = $html->find( ‘.sub’ ); |
【4】抽出した値を配列型の変数に代入して、ブラウザ上に書き出すようにHTMLコードを生成させます。
クラス属性が「catch_copy」である要素があれば、繰り返し全部(=foreach(){ })、それを配列(=$parts[0])に代入し、ブラウザ上に書き(=echo)出します。
| foreach($html–>find(‘.catch_copy’) as $parts[0]){ echo $parts[0]; } |
それでは、実際にコードをかいてみて、「index.php」のファイル名で保存しましょう。
仮に取りだしたい商品ページについて
1)商品IDが「15000」として、
2)商品ページのURLが「http://sample.com/shouhin/15000/」と仮定します。
ブラウザ上で、「15000」と入力して送信ボタンを押すと、商品ページの情報を抽出してブラウザ上に表示されるようにコードを組んでいきます。
まずは、結果から。
ブラウザで「index.php」ファイルをひらきます。
レンタルサーバーのURLで開くなら、アドレスバーに「http://サーバー名/フォルダ名/index.php」と入力します。PCにXAMPPをインストールし,PHPファイルを[htdocs]フォルダの直下に保存したなら、XAMPPを起動し、アドレスバーに「localhost/index.php」と入力します。
ブラウザに下のような入力フォームと送信ボタンが表示されます。
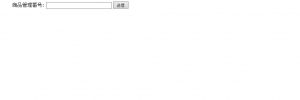
フォームに「15000」と入力し、送信ボタンを押します。
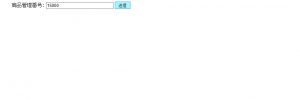
すると、下のように商品IDが15000の商品ページの情報が取得され、表示されます。

では、PHPファイルを作りましょう。
メモ帳にコードを書いて、ファイル名を「index.php」で保存すればOKです。
スクレイピングしたいURLは、「http://item.rakuten.co.jp/shopurl/15000/」(=$site)です。
①きまり文句です。
②ライブラリのsimple_html_dom.phpを呼び込みます。
③webページへのリクエスト送信方法を「POST」で行います。(「POST」か「GET」で指定する必要がありますが、理解することは不要です。「POST」で宣言すればいいので、定型文的なものと考えてください。)
④URL(=$site)から、ヘルパー関数(=file_get_html)を使ってオブジェクト(=$html)を生成(スクレイピング)します。
⑤商品IDとして、フォームのテキスト入力欄に入力した値(=’15000’)を取得します。
※商品IDはフォームに入力した値(=site)から取得(=$_POST[‘site’])します。
⑥生成したオブジェクト(=$html)から、特定のクラス名を持つ要素を探し出し、配列(=$parts[])に代入し、ブラウザ上に書き(echo)出します。
| <?php /********************************************** リクエストURLの生成 ************************************************/ //カレント言語を日本語に指定mb_language(“Japanese”); mb_language(“Japanese”);・・・・① //PHP内部のエンコーディングを’UTF-8’に指定 mb_internal_encoding (“utf-8”); ・・・・① session_start(); ・・・・① //simple_html_dom.phpファイルの読み込み include_once(‘simplehtmldom_1_5/simple_htmldom.php’); ・・・・② //フォームからURL取得 $site=”; if ($_SERVER[‘REQUEST_METHOD’] === ‘POST’) {$site = htmlspecialchars(‘http://item.rakuten.co.jp/shopurl/’.$_POST[‘site’].’/’); ・・・・③ $err = false; //スクレイピングしたいURLを指定 //「simple_html_dom.php」のヘルパー関数を利用してスクレイピング $html = file_get_html($url); ・・・・④ header(“Content-type:text/html;charset=UTF-8”); ・・・・① ?> <html lang=”ja”> <!–##################################################### (1)商品管理番号より、商品ページのURLを取得 ####################################################–> //フォームの部品(テキスト入力欄)を作成し、入力された値を取得する。 <span>商品管理番号:</span> </form> //要素を抽出して、書き出す。 <h2><?php echo$_POST[‘site’]; ?>の要素を抽出します。</h2><br> </table> <?php } ?> <style type=”text/css”> –> |
以上は、楽天の商品ページから特定の要素を抜き出し、ブラウザに書き出すphpです。
楽天の商品ページを開いて「F12」キーを入力すると開発者用のウィンドウが表示されますが、そこで、特定の要素が含まれるドキュメントを確認すると、それぞれ、特定のクラス名が自動で付けられていることが確認できます。
これを利用して、すでにアップした商品ページから情報を抜き取ることに成功しました!
次に、カテゴリページの商品IDを取りだします
同様にして、楽天の新着情報ページ(検索結果ページ)に表示されている複数の商品の商品IDを抽出してみます。
新着情報ページが3ページ目の場合のURLは「http://search.rakuten.co.jp/search/mall/ブランドスーパー楽天市場店/?p=3&s=4&v=3」です。3ページ目の場合、クエリ文字列(?—)の変数「p」に対して取る値が「3」なので、クエリ文字列は「?p=3&・・・」で表されます。同様に4ページ目の場合はクエリ文字列は「?p=4&・・・」となります。
フォームのテキストエリアに何ページ目の情報を取得するのか入力して、送信ボタンを押すと結果が返るようにコードを組んでいきます。
まずは、結果から。
ブラウザで「index.php」ファイルをひらきます。
ブラウザに下のような入力フォームと送信ボタンが表示されます。
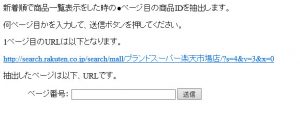
フォームに「3」と入力し、送信ボタンを押します。
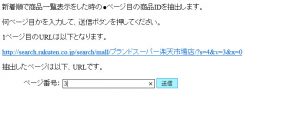
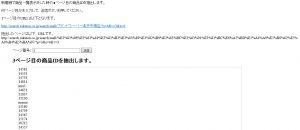
すると、下のように3ページ目に表示されている商品の商品IDの情報が取得され、表示されます。
では、PHPファイルを作りましょう。
スクレイピングしたいURLは、3ページ目の「http://search.rakuten.co.jp/search/mall/ブランドスーパー楽天市場店/?p=3&s=4&v=3」(=$site)です。考え方は商品ページから情報を抽出する時と同じです。
※URLでかな文字は使えませんので、「ブランドスーパー楽天市場店」の部分はパーセントコードに変換(エンコード)しておきます。
「ブランドスーパー楽天市場店」⇒「%83u%83%89%83%93%83h%83X%81%5b%83p%81%5b%8ay%93V%8es%8f%ea%93X」
| <?php /********************************************** リクエストURLの生成 ************************************************/ //カレント言語を日本語に指定 mb_language(“Japanese”);//PHP内部のエンコーディングを’UTF-8’に指定 mb_internal_encoding (“utf-8”);session_start();//simple_html_dom.phpファイルの読み込み<br> include_once(‘simplehtmldom_1_5/simple_html_dom.php’);//フォームからURL取得 $site=”; $url=”; $html=”; if ($_SERVER[‘REQUEST_METHOD’] === ‘POST’) {$site = htmlspecialchars(‘http://search.rakuten.co.jp/search/mall/%E3%83%96%E3%83%A9 %E3%83%B3%E3%83%89%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E6%A5 %BD%E5%A4%A9%E5%B8%82%E5%A0%B4%E5%BA%97/ ?p=’.$_POST[‘site’].’&s=4&v=3′);$err = false;//スクレイピングしたいURLを指定<br> $url = $site;//「simple_html_dom.php」のヘルパー関数を利用してスクレイピング $html = file_get_html($url); }header(“Content-type:text/html;charset=UTF-8”); ?> <html lang=”ja”> <head> <meta http-equiv=”content-type” content=”text/html; charset=UTF-8″> <title>「<?php echo$_POST[‘site’]; ?>」ページ目の商品IDの抽出</title></head> <body> <p>新着順で商品一覧表示をした時の●ページ目の商品IDを抽出します。</p> <P>何ページ目かを入力して、送信ボタンを押してください。</P> <P>1ページ目のURLは以下となります。</P> <a href=”http://search.rakuten.co.jp/search/mall/%E3%83%96%E3%83%A9%E3%83%B3 %E3%83%89%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E6%A5%BD%E5%A4 %A9%E5%B8%82%E5%A0%B4%E5%BA%97/?s=4&v=3&x=0″ target=”_blank”><p>http://search.rakuten.co.jp/search/mall/ブランドスーパー楽天市場店/?s=4&v=3&x=0</p></a> <p>抽出したページは以下、URLです。<br><?php echo $site;?></p><div style=”margin-left:50px;”><form action=”<?php echo $_SERVER[‘PHP_SELF’]; ?>” method=”post”> <span>ページ番号:</span> </form> <?php if($_POST[‘site’]){ ?> <h2><?php echo$_POST[‘site’]; ?>ページ目の商品IDを抽出します。</h2><br> <div> <tr> <?php foreach($html->find(‘.price > a‘) as $part){ ?> <?php $pieces = explode(“/”, $part->href); ?> <?php } ?> </td> </table> <?php } ?> <style type=”text/css”> } |
前回に追加した内容としては、要素を抽出する際の手法です。検索結果ページ内に表示されている商品のリンク先情報に各商品IDの情報が含まれているので、
まずリンク先情報を取り出します。
| $html->find(‘.price > a‘) as $part |
└※クラス名が「price」の<a>タグの情報を探し、$partに代入する
さらに、取り出したリンク先情報のURLを「/」で分割し、配列($pieces)に代入して、4番目の値($pieces[4])を取り出します。
取り出した値が商品IDとなるので、これを列挙します。
| $pieces = explode(“/”, $part->href); echo $pieces[4].'<br>’; |
以上、足早に書いてきましたが、何かのヒントになりますか?
得た知識をリアルな現場に応用して、日々の作業を軽くしていきましょう!